ロボットの顔のモーフィング
IM-NETを使った3Dモデルのモーフィング処理ですが、これまでに集めたロボット頭部のデータをIM-NETに学習させてみました。
1.2つのロボット頭部の3DボクセルデータをそれぞれIM-NETエンコーダで処理
2.得られ2つのたコード(256次元)を加重平均
3.平均ベクトルをIM-NETデコーダで処理、MarchingCubeで3Dサーフェスを復元

加重平均の重みを連続的に変化させてみるとこんな感じ。

ほかにもいくつか試してみました。


例えば以下の2つの元データから、

加重平均の重みを変えてみると元データのどちらとも少しずつ異なる形状が生成されていることがわかります。

IM-NETを使ったモーフィングによる3D形状作成では、アンテナなどのとんがった形状がなまってしまうという難点はあるものの、3Dの形状として成立するデータを生成できることが確認できました。
学習用3Dデータの準備に関する備忘録
IM-NETのプログラムが掲載されているgitのリポジトリには学習用の3Dデータをどこから取得するかという点についても記述がありました。ShapeNetとうい3Dデータを集めるプロジェクトがあるんですね。
Robotの顔なんていう特殊なカテゴリはありませんが、airplaneとかcarとかの3Dデータが3万個ぐらいはあるので、thingiverseから集めたロボットの顔データと組み合わせればよい学習ができそうです。
ShapeNetのデータはmat形式というmatlabで使われている形式で格納されています。scipyパッケージを使ってロードできますが、簡単なデータ圧縮が行われている状態で読み込まれるようです。圧縮を伸長して256x256x256のボクセルデータを得るコードはこんな感じ。
from scipy.io import loadmat
voxel_model_mat = loadmat(filename)
voxel_model_b = voxel_model_mat['b'][:].astype(np.int32)
voxel_model_bi = voxel_model_mat['bi'][:].astype(np.int32)-1
voxel_model_256 = np.zeros([256,256,256],np.uint8)
for i in range(16):
for j in range(16):
for k in range(16):
voxel_model_256[i*16:i*16+16,j*16:j*16+16,k*16:k*16+16]
= voxel_model_b[voxel_model_bi[i,j,k]]
#古いShpapeNetのフォーマットとの座標系の違いを補正
voxel_model_256 = np.flip(np.transpose(voxel_model_256, (2,1,0)),2)
上記の例だと縦、横、高さで256x256x256のデータが16x16x16個の小区画(1区画は16x16x16のボクセルデータ)に分割され”b”に1次元配列として格納されています。"bi"の3次元配列は”b”の1次元配列へのインデックスを保持しています。形状の外側は16x16x16のボクセルデータが全部0、内側は全部1になることが多いので1次元配列の長さは16x16x16=4096をワーストケースとして通常はそれよりもだいぶ短くできるわけです。
あとOBJ形式のサーフェスモデルからボクセルデータを生成する処理を自作のプログラムからshapeNet推奨のbinvoxに乗り換えることにしました。binvoxのほうが速いしサーフェスの内部を埋める処理を私のいいかげんプログラムより正確にやってくれるからです。
binvox -rotz -rotz -rotx -rotx 5073_Spiderman_Bust_v1.04.obj
-rotz -rotxはShapeNetと私のデータとで前後の向きが逆だったのでその補正をしています。出力はbinvoxという形式ですがbinvox_rwというパッケージで簡単に生の3次元データを抜き取ることができます。
import binvox_rw as bv_rw
with open(file_name, 'rb') as f:
model = bv_rw.read_as_3d_array(f).data
model2 = model.reshape([model.shape[0], model.shape[1],
model.shape[2]]).astype(np.uint8)
state-of-the-artのDeep Learning(IM-NET)を試してみた
前回、Deep Learningを使った3Dデータのモーフィングを試してみて、なんらかの形を作ってはくれるもののちょっと残念な結果に終わったわけですが、我流で進めるのもそろそろ限界かなと思いちょっと世の中の状況を調べてみました。さすがに日本語の書籍で3Dモデルの生成を扱っているようなものはまだないですが、論文ではいくつか発表されていました。
そのうちの1つが2019年のCVPR(Computer Vision and Pattern Recognition)で発表された
Learning Implicit Fields for Generative Shape Modeling
で、オートエンコーダのデコーダ部分(IM-NET)に大きな特徴があります。通常、エンコーダが出力した何次元かのコード情報から、転置畳込み層とMax pooling層を使って3次元のボクセルまたはサーフェスのデータを作っていくのですが、IM-NETではコードと3次元の点の座標を受け取ってその点がコードが表す形状の内側にあるのか外側にあるのかを出力するネットワークを学習していきます。ある程度の数の点について形状の内側か外側かがわかったところでMarching Cubeというアルゴリズムを走らせて内と外の境界をサーフェス(メッシュ)として出力します。
ちなみにCVPRという国際会議は30年以上前の研究所勤務の時代には文字認識関係の論文を漁ったりしていたこともあるのですが、まさか会社を辞めてからまた論文を読むことになるとは思わなかった...
昔と大きく異なるのは、私のころは国際会議の論文にアクセスするには海外の会議に出席するか高価な予稿集を購入するかしか方法がなかったのが、いまはネットで簡単に論文を読むことができるということ。さらに、論文内容を実装したプログラムや実験に使ったデータまでgitHubから手にいれることができます。公開されているPytorchを使った実装とデータを使ってオートエンコーダの処理を私の環境でも動かすことができました。そこからちょっとだけプログラムを変えてcarの3Dモデルとairplaneの3Dモデルとの間でモーフィングを行ってみました。

我流で行ったモーフィングよりも断然スムーズに形状が変化していってる!
次は自分で集めたロボットの頭部データをIM-NETの学習データに取り込んでロボット頭部のモーフィングを試してみたいと思っています。
ロボットの頭部をAIでデザインできないかと試してみたい ーVAEでモーフィングー
前回のブログの終わりに法線ベクトルを使った3Dモデル(VAE:変分オートエンコーダ)の学習を実行中と書きましたがその結果がやっとでました。あれから2週間以上もコンピュータを動かしつづけたわけではなくて、結果を確認してみたら学習に失敗していて何回か計算をやりなおすはめになったからです。ネットワークの構成としてはだいたいかたまっていたのですがいくつかのハイパーパラメータ(データから学習するのではなくて人間があらかじめ決めておかかなければならないパラメータ)、具体的にはエンコーダの出力ベクトル長、最適化アルゴリズム(Adam)の学習率、損失を計算するときのKL情報量の重みといったあたりについては試行錯誤を繰り返して設定する必要がありました。
特にKL情報量の重みは書籍に載っているVAEのプログラムの値より(対象が違うから当然といえば当然ですが)だいぶ小さくしないとだめでした。不適切な設定だと損失関数の値は小さな値に最適化されていくのですが、作られている形状をみてみると何もないからっぽということが多かったです。もともとの形状データでも64x64x64個の点のうち意味のある値(0以外の値)を持つのはごく一部です。何を入力されてもみんな値0のからっぽの3Dデータを出力すれば元の入力との差異(損失関数の値)をそこそこには小さくできる、という方針で最適化を行ってしまっているようです。
それやこれやで、なんとかVAEの学習ができているところまで達したと思えたので3Dデータのモーフィングを試してみました。

モーフィング処理の考え方を簡単に記すと以下のようになります。
1.学習済エンコーダーネットワークに既存の3dデータモデルAを入力してベクトルデータVA(今回は64次元)を得る
2.同様に既存の3dデータモデルBをエンコーダネットワークに入力してベクトルデータVBを得る
3.VAとVBの重みつき(以下の例では0.5:0.5)平均VXを計算する。
4.学習済デコーダネットワークにVXを入力して新規の3Dデータモデルを得る
上記の画像には3つの3Dデータモデル(それぞれ正面と側面)が表示されていますが、左端と右端のモデルは学習に用いたデータ(上述のAとB)です。正確に言えば、AをエンコーダでVAに変換してからさらにデコーダで復元したA’(Aダッシュ)です。AとA'が等しくなるようにエンコーダとデコーダの重みを学習したわけですが、現状ではなんとか似たような形状を出力しているといったところでしょうか。真ん中のデータモデルはVAとVBの平均VXをデコーダに入力して得られたもので、AとBの面影はあるものの学習データのセットには存在していなかった形状になります。

3Dデータのモーフィング例(2)

この結果を観て思ったこと、肯定的な評価と否定的な評価の両方。
まず、肯定的な評価としては面が閉じている頭部パーツとしてそれなりに成立している形状が作成できていること。64個の数値から64x64x64x3個のデータが生成されてひとつながりの面データを表現できているのは「すごい!」と思いました。
否定的な評価として、アンテナなど形状を特徴づけるとんがった部分がエンコーディング/デコーディングの過程で失われていく傾向があることですね。実際、モーフィング以前の問題として上述のAとA'(Aダッシュ)を比べてみると細めのアンテナっぽい形状は失われてしまっている。いわゆる周波数の低い成分しか残らない。

デザインの支援に使うという意味ではむしろアンテナのような特定の形状を強調したいのですが、どうしたらいいのだろう? まだまだ試行が続きそうです。
ロボットの頭部をAIでデザインできないかと試してみたい ー3Dモデル表現方法の変更ー
これまでDeep Learningの入力/出力となるデータとして例えば1x64x64x64といった形式のNumpyデータを使ってきました。64というのは空間をX方向、Y方向、Z方向に分割するときの解像度(数字が大きいほど形状を細かく表現できる)ですが、残った1次元(1チャネル)は64x64x64で区切られた小区画の中にサーフェスモデル(OBJ形式)の頂点が存在する確率になります。VAEやGANのネットワークで生成する3Dデータもこの形式なので、実際にネットワークの出力結果を3Dのモデラーで使うためにはNumpy形式のデータからOBJ形式に変換しなければなりません。OBJ形式には頂点だけではなく3または4個の頂点で作られる面の情報が必要なので、点データの近傍を検索して貪欲算法で近傍点とで構成する面を出力するというプログラムを作ってOBJ形式データを作っていました。
で、今回はDeep Learningのネットワークがどうこうという以前にOBJ形式⇒1チャネルのNumpy配列⇒OBJ形式という変換をやってみてどのくらい元の形状を再現できるのか、というのがテーマです。
以下はテストに使ったオリジナルの3Dモデルです。Thingiverseで見つけたモデルをZBrushで読み込んだ後ダイナメッシュで細かいメッシュのモデルに変案しています。

ニューラルネットで処理できるよう1x64x64x64のNumpy配列に変換します。これをmatplotlibで表示するとこんな感じです。
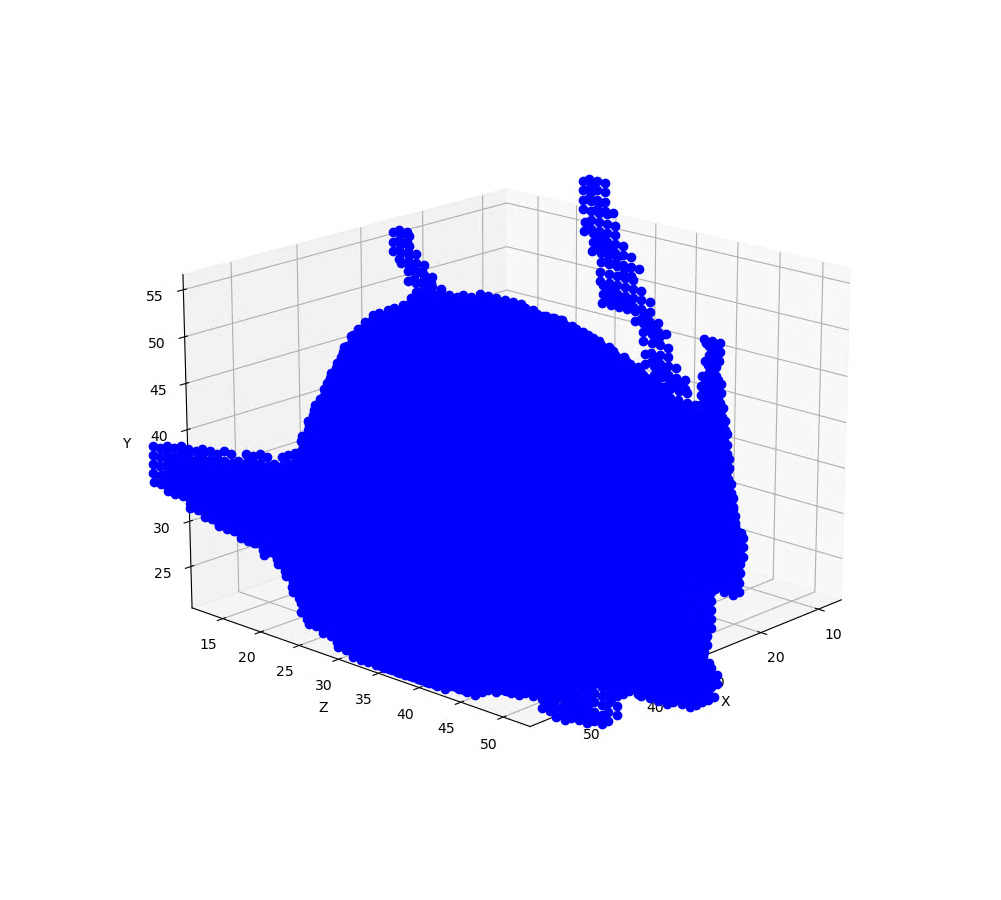
だいたいの形状は表現できていると思うのですが、これを上述の貪欲算法のプログラムでOBJ形式に変換して表示してみると、ちょっと残念な感じになってしまいました。

近傍の点同士を面としてつなげる閾値の設定にもよるのですが、目とか耳のあたりの凹凸が埋まってわからなくなっている反面、ちょっと細めのアンテナは消えてしまっています。ちなみにMeshLabなどのツールでは一様でない点群データからサーフェスを生成する一般的なアルゴリズム(ボールピボットアルゴリズムというのがあるらしい)を実装していますが、これを単純に適用した結果は上記よりもさらに残念なものでした。なんとなくこんなもんかと思って、この形式のNumpyデータをニューラルネットの入力に使っていたのですが、これだとネットの学習がうまくいって良いデータが生成されたとしてもOBj形式に変換するときに劣化してしまいます。
今回、もうちょっとなんとかしたいということで考えたのはもともとのOBJ形式がもっていた面の情報をNumpy形式データに取り込むこと。具体的にはある区画に頂点が存在するかという1チャンネルの情報ではなく、頂点を含む面の方向、正確には頂点を含む面に垂直なベクトル(法線ベクトル)を示す3チャンネルの情報を使うことにしました。OBJ形式データには頂点とその頂点が構成する面の情報があるので、面に対する法線ベクトルを計算して3x64x64x64のNumpyデータを出力します。NumpyデータからOBJ形式に復元するさいには、法線ベクトルと垂直な平面上に位置する近傍点を優先して面データを作成します。3x64x64x64のNumpyデータからこの方式でOBJを復元すると以下のようになりました。

オリジナルにはおよばないもののだいぶ形状を復元できるようになりました。
Pytorchの使い方もわかってきたところで、現在3x64x64x64のデータでVAE(変分オートエンコーダ)の学習をおこなっています(いまいま、まる4日PCを動かし続けている…)。どんな3Dデータが生成できているか、期待しながら待っているところです。
Pytorchの勉強を続ける
Pytorchの勉強を続けています。前回、基本的なGANは動いたと書きましたがどうもうまく学習できていないみたい・・・
オートエンコーダ(AE)のほうが学習状況の確認がしやすい(損失関数が1つだけなのでこいつが単調に減少していってくれればいちおう学習が進んでいると判断できる)ので、基本のAEまで戻ってプログラムしています。
今作っているAEは入力(下図の左)の3Dデータ(32x32x32)をエンコーダネットワークで100次元のベクトルに変換し、このベクトルをデコーダネットワークで元のサイズ(32x32x32)の3Dデータ(下図の右)に変換しています。

単純なAEだと損失関数としてエンコーダの入力とデコーダの出力の差(Binary Cross Entropy)を使うのですが、今回は出力が値のばらつきが正規分布になっているかというKL-Divergence(カールバックライブラーダイバージェンス)の項を追加しています。変分オートエンコーダと呼ばれています。

エンコーダへの入力とデコーダの出力の例 (2)
KL項の重みをどのくらいにするかにもよるのですが、変分オートエンコーダでは角やアンテナなどの特徴が失われてしまうことが多いです。

比較的学習しやすい変分オートエンコーダとシャープな出力が得られるGANを組み合わせるという手法もあるようです。
ロボットの頭部をAIでデザインできないかと試してみたい ーフレームワークをPytorchに変更ー
これまで3Dモデル生成のネットワークを作るのにTensorflow/Kerasというフレームワークを使っていたのですが、しばらく前からPytorchというフレームワークを使ってプログラムを作っています。2つのフレームワークはDeep Learning用フレームワークの2大勢力です。tensorflowが機能的に何か足りないとかということはないのですが、tensorflowでGANのプログラムをいじっているとフレームワークの中で発生したエラーの原因を特定できず煮詰まってしまっていて、何か目先を変えて打開したいというのがPytorchに手をだした理由です。
試行錯誤を続けてVisual Source CodeのJupyterプラグイン使ってデバッグするやりかたがやっとわかってきました。基本的なGANで32x32x32の3Dモデル(numpy配列)を作れるようになったところです。
損失関数の値をグラフにするやりかたもやっとわかってきました(これはDeep Learning)関係なくて単にPythonプログラミングをわかってなかっただけなんですが)。生成器の損失関数の値が学習をかさねるにつれて(乱高下しながらも)下がっていることがわかります。

実際、同じ初期値をネットワークに入力しても学習が進んだネットワークからの出力はなんとなくロボットの頭部っぽい形が出力されています。

プログラムとしては動いてくれていると思うのですが、ネットワークの学習の状況としてはまだまだです。モード崩壊とよばれる現象がおこっているらしく生成される形にバリエーションがないんですよね。ランダムに発生させたいろんな初期値を与えても生成される形は2,3個のパターンのどれかに落ちてしまう...
対応するための手法はいくつかあるので今後試していく予定です。